The key technologies behind SQL Comprehension

You ever wonder what’s really going on in your database when you fire off a (perfect, efficient, full-of-insight) SQL query to your database?
OK, probably not 😅. Your personal tastes aside, we’ve been talking a lot about SQL Comprehension tools at dbt Labs in the wake of our acquisition of SDF Labs, and think that the community would benefit if we included them in the conversation too! We recently published a blog that talked about the different levels of SQL Comprehension tools. If you read that, you may have encountered a few new terms you weren’t super familiar with.
In this post, we’ll talk about the technologies that underpin SQL Comprehension tools in more detail. Hopefully, you come away with a deeper understanding of and appreciation for the hard work that your computer does to turn your SQL queries into actionable business insights!
Here’s a quick refresher on the levels of SQL comprehension:
 The three levels of SQL Comprehension, with example SQL.
The three levels of SQL Comprehension, with example SQL.Each of these levels is powered by a distinct set of technologies. It’s useful to explore these technologies in the context of the SQL Comprehension tool you are probably most familiar with: a database! A database, as you might have guessed, has the deepest possible SQL comprehension abilities as well as SQL execution abilities — it contains all necessary technology to translate a SQL query text into rows and columns.
Here’s a simplified diagram to show your query’s fantastic voyage of translation into tabular data:
 A flow chart showing a SQL query's journey to raw data.
A flow chart showing a SQL query's journey to raw data.First, databases use a parser to translate SQL code into a syntax tree. This enables syntax validation + error handling.
Second, database compilers bind metadata to the syntax tree to create a fully validated logical plan. This enables a complete understanding of the operations required to generate your dataset, including information about the datatypes that are input and output during SQL execution.
Third, the database optimizes and plans the operations defined by a logical plan, generating a physical plan that maps the logical steps to physical hardware, then executes the steps with data to finally return your dataset!
Let’s explore each of these levels in more depth!
Level 1: Parsing
At Level 1, SQL comprehension tools use a parser to translate SQL code into a syntax tree. This enables syntax validation + error handling. Key Concepts: Intermediate Representations, Parsers, Syntax Trees
 Parsers can model the grammar and structure of code.
Parsers can model the grammar and structure of code.Intermediate representations
Intermediate representations are data objects created during the process of compiling code.
Before we dive into the specific technologies, we should define a key concept in computer science that’s very relevant to understanding how this entire process works under the hood: an Intermediate Representation (IR). When code is executed on a computer, it has to be translated from the human-readable code we write to the machine-readable code that actually does the work that the higher-level code specifies, in a process called compiling. As a part of this process, your code will be translated into a number of different objects as the program runs; each of these is called an intermediate representation.
To provide an example / analogy that will be familiar to dbt users, think about what your intermediate models are in the context of your dbt DAG — a translated form of your source data created in the process of synthesizing your final data marts. These models are effectively an intermediate representation. We’re going to talk about a few different types of IRs in this post, so it’s useful to know about them now before we get too deep!
Parsers
Parsers are programs that translate raw code into syntax trees.
All programming languages require a parser, which is often the first step in the translation process from human-readable to machine-readable code. Parsers are programs that can map the syntax, or grammar, of your code into a syntax tree, and understand whether the code you wrote follows the basic rules of the language.
In computing, parsers have a few underlying pieces of technology that build the syntax tree that understands the relationships between your variables, functions, and classes, etc. The components of a parser include:
- a lexer, which takes raw code strings, and return lists of tokens recognized in the code (in SQL,
SELECT,FROM, andsumwould be examples of tokens recognized by a lexer) - a parser, which takes the lists of tokens generated by a lexer, and builds the syntax tree based on grammatical rules of the language (i.e. a
SELECTmust be followed by one or more column expressions, aFROMmust reference a table, or CTE, or subquery, etc).
In other words, the lexer first detects the tokens that are present in a SQL query (is there a filter? which functions are called?) and the parser is responsible for mapping the dependencies between them.
A quick vocab note: while technically, the parser is only the component that translates tokens into a syntax tree, the word “parser” has come to be shorthand for the whole process of lexing and parsing.
Syntax trees
Syntax trees are a representation of a unit of language according to a set of grammatical rules.
Your first introduction to understanding syntactical rules probably came when you learned how to diagram sentences in your grade school grammar classes! Diagramming the parts of speech in a sentence and mapping the dependencies between each of its components is precisely what a parser does — the resulting representation of the sentence is a syntax tree. Here’s a silly example:
My cat jumped over my lazy dog
By parsing this sentence according to the rules of the English language, we can get this syntax tree:
 Apologies to my mother, an english teacher, who likely takes umbrage with this simplified example
Apologies to my mother, an english teacher, who likely takes umbrage with this simplified exampleLet’s do the same thing with simple SQL query:
select
order_id,
sum(amount) as total_order_amount
from order_items
where
date_trunc('year', ordered_at) = '2025-01-01'
group by 1
By parsing this query according to the rules of the SQL language, we get something that looks like this:
 This is a simplified syntax tree — This was made by hand, and may not be exactly what the output of a real SQL parser looks like!
This is a simplified syntax tree — This was made by hand, and may not be exactly what the output of a real SQL parser looks like!The syntax trees produced by parsers are a very valuable type of intermediate representation; with a syntax tree, you can power features like syntax validation, code linting, and code formatting, since those tools only need knowledge of the syntax of the code you’ve written to work.
However, parsers also dutifully parse syntactically correct code that means nothing at all. To illustrate this, consider the famous sentence developed by linguistics + philosophy professor Noam Chomsky:
Colorless green ideas sleep furiously
That’s a perfectly valid, diagrammable, parsable sentence according to the rules of the English language. But that means absolutely nothing. In SQL engines, you need a way to imbue a syntax tree with additional metadata to understand whether or not it represents executable code. As described in our first post, Level 1 SQL Comprehension tools are not designed to provide this context. They can only provide pure syntax validation. Level 2 SQL Comprehension tools augment these syntax trees with meaning by fully **compiling **the SQL.
Level 2: Compiling
At Level 2, SQL comprehension tools use a compiler to bind metadata to the syntax tree to create a fully validated logical plan. Key concepts: Binders, Logical Plans, Compilers

Binders
In SQL compilers, binders are programs that enhance + resolve syntax trees into logical plans.
In compilers, binders (also called analyzers or resolvers) combine additional metadata with a syntax tree representation and produce a richer, validated, executable intermediate representation. In the above English language example, in our heads, we’re binding our knowledge of the definitions of each of the words to the structure of the sentence, after which, we can derive meaning.
Binders are responsible for this process of resolution. They must bind additional information about the components of the written code (their types, their scopes, their memory implications) to the code you wrote to produce a valid, executable unit of computation.
In the case of SQL binders, a major part of its job is to add warehouse schema information, like column datatypes, with the type signatures of warehouse operators described by the syntax tree to bring full type awareness to the syntax tree. It’s one thing to recognize a substring function in a query; it’s another to understand that a substring must operate on string data, and always produces string data, and will fail if you pass it an integer.
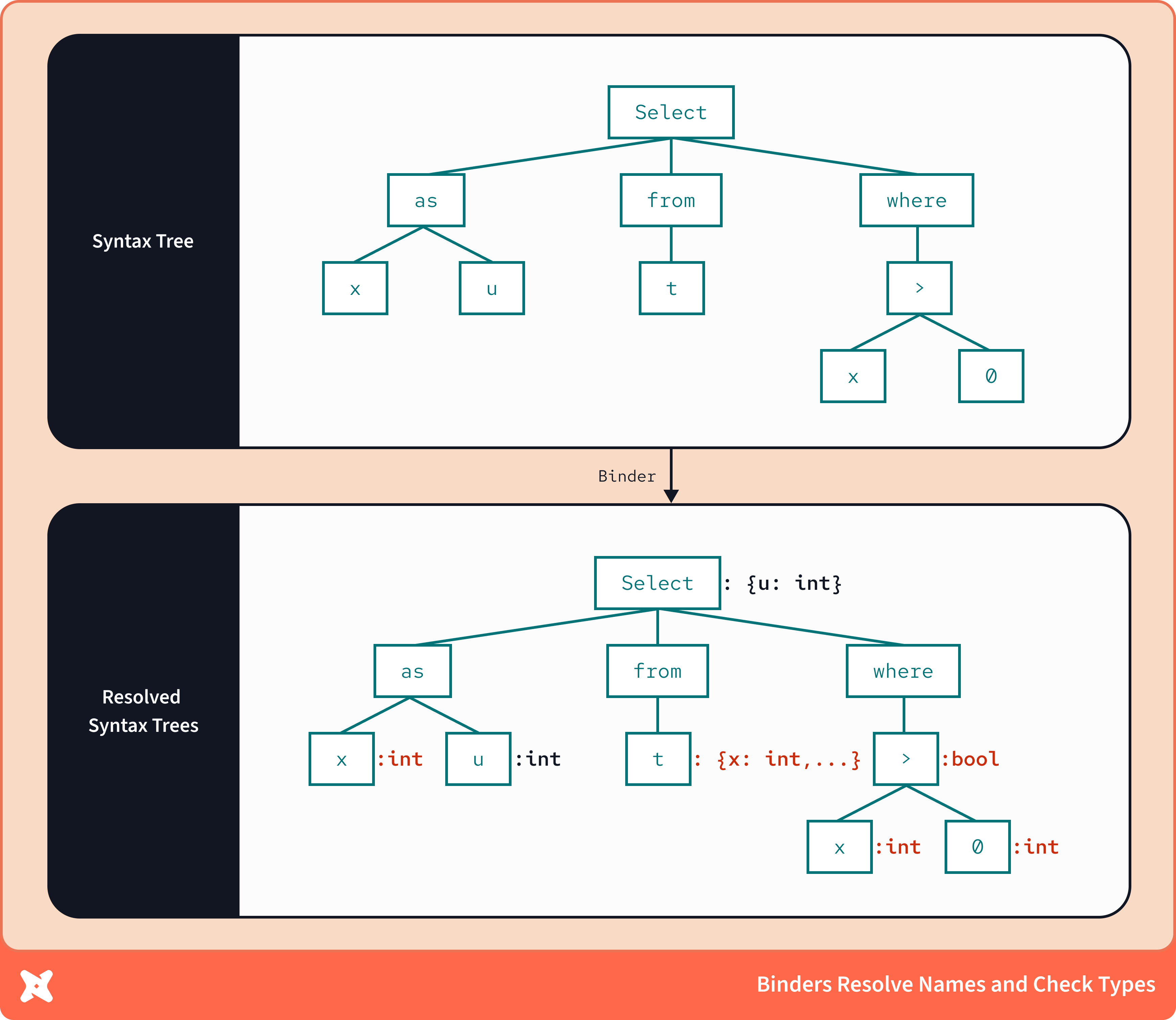
In this example, while the syntax tree knows that the x column is aliased as u, the binder has the knowledge that x is indeed a column of type int and therefore, the resulting column u must also be of type int. Similarly, it knows that the filter condition specified will produce a bool value, and therefore must have compatible datatypes as its two arguments. Luckily, the binder can also see that x and 0 are both of type int, so we're confident this is a fully valid expression. This layer of validation, powered by metadata, is referred to as type awareness.
In addition to being able to trace the way datatypes will flow and change through a set of SQL operations, the function signatures allow the binder to fully validate that you’ve provided valid arguments to a function, inclusive of the acceptable types of columns provided to the function (e.g. split_part can’t work on an int field) as well as valid function configurations (e.g. the acceptable date parts for datediff includes 'nanosecond' but not 'dog_years').
Logical plan
In SQL compilers, logical plans define the validated, resolved set of data processing operations defined by a SQL query.
The intermediate representation output by a binder is a richer intermediate representation that can be executed in a low level language; in the case of database engines, this IR is known as a Logical Plan.
Critically, as a result of the binder’s work of mapping data types to the syntax tree, logical plans have full data type awareness — logical plans can tell you precisely how data flows through an analysis, and can pinpoint when datatypes may change as a result of, say, an aggregation operation.
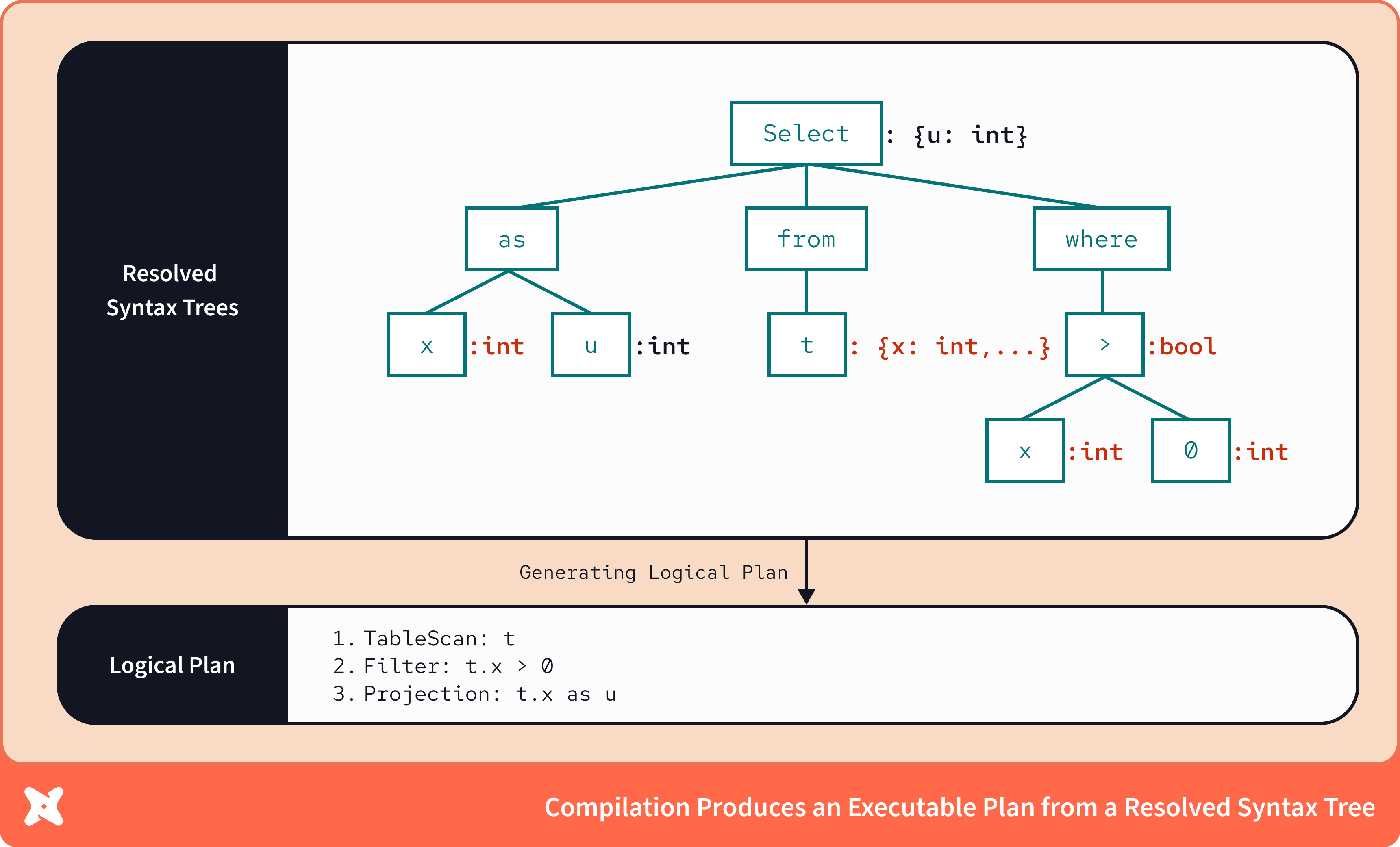
You can see we’ve gotten a more specific description of how to generate the dataset. Rather than simply mapping the SQL keywords and their dependencies, we have a resolved set of operations, in this case scanning a table, filtering the result, and projecting the values in the x column with an alias of u.
The logical plan contains precise logical description of the computing process your query defined, and validates that it can be executed. Logical plans describe the operations as relational algebra, which is what enable these plans to be fully optimized — the steps in a logical plan can be rearranged and reduced with mathematical equivalency to ensure the steps are as efficient as possible.
This plan can be very helpful for you as a developer, especially if it’s available before you execute the query. If you’ve ever executed an explain function in your database, you’ve viewed a logical plan! You can know exactly what operations will be executed, and critically, you can know that they are valid! This validity check pre-compute is what is referred to as static analysis.
Compilers
Compilers are programs that translate high-level language to low-level language. Parsers and binders together constitute compilers.
Taken together, a parser plus a binder constitute a compiler, a program that takes in high-level code (one that is optimized for human readability, like SQL) and outputs low-level code (one that is optimized for machine readability + execution). In SQL compilers, this output is the logical plan.
A compiler definitionally gives you a deeper understanding of the behavior of the query than a parser alone. We’re now able to trace the data flows and operations that we were abstractly expressing when we initially wrote our SQL query. The compiler incrementally enriches its understanding of the original SQL string and results in a logical plan, which provides static analysis and validation of your SQL logic.
We are however, not all the way down the rabbit hole — a compiler-produced logical plan contains the full instructions for how to execute a piece of code, but doesn’t have any sense of how to actually execute these steps! There’s one more translation required for the rubber to fully meet the motherboard.
Level 3: Executing
At Level 3, the database’s execution engine translates the logical plan into a physical plan, which can finally be executed to return a dataset. Key concepts: Optimization and Planning, Engines, Physical plans
Optimization and planning
A logical plan goes through a process of optimization and planning that maps its operations to the physical hardware that is going to execute each step.
Once the database has a resolved logical plan, it goes through a process of optimization and planning. As mentioned, because logical plans are expressed as relational algebraic expressions, it can choose to execute equivalent steps in whichever order it chooses.
Let’s think of a simple example SQL statement:
select
*
from a
join b on a.id = b.a_id
join c on b.id = c.b_id
The logical plan will contain steps to join the tables together as defined in SQL — great! Let’s suppose, however, that table a is several orders of magnitude larger than each of the other two. In that case, the order of joining makes a huge difference in the performance of the query! If we join a and b first, then the result ab with c, we end up scanning the entirety of the extremely large table a twice. If instead we join b and c first, and join the much smaller result bc with table a , we get the same result of abc at a fraction of the cost!
Layering in the knowledge of the physical characteristics of the objects referenced in a query to ensure efficient execution is the job of the optimization and planning stage.
Physical plan
A physical plan is the intermediate representations that contains all necessary information to execute the query.
Once we do the work to decide on the optimal plan with details about the physical characteristics of the data, we get one final intermediate representation: the physical plan. Think about the operations defined by a logical plan — we may know that we have a TableScan operation of a table called some_table. A physical plan is able to map that operation to specific data partitions in specific data storage locations. The physical plan also contains information relevant to memory allocation so the engine can plan accordingly — as in the previous example, it knows the second join will be a lot more resource intensive!
Think about what your data platform of choice has to do when you submit a validated SQL query: the last mile step is deciding which partitions of data on which of its servers should be scanned, how they should be joined and aggregated to ultimately generate the dataset you need. Physical plans are among the last intermediate representations created along the way to actually returning data back from a database.
Execution
A query engine can execute a physical plan and return tabular data
Once a physical plan is generated, all that’s left to do is run it! The database engine executes the physical plan, and fetches, combines, and aggregates your data into the format described by your SQL code. The way that the engine accomplishes this can vary significantly depending on the architecture of your database! Some databases are “single node” in that there is a single computer doing all the work; others are “distributed” and can federate the work across many working compute nodes.
In general, the engine must:
-
Allocate resources — In order to run your query, a computer must be online and available to do so! This step allocates CPU to each of the operation in the physical plan, whether it be one single node or many nodes executing the full query task
-
Read Data Into Memory — The tables referenced are then scanned as efficiently as possible, and the rows are processed. This may happen in partial stages depending on whether the tasks are distributed or happening within one single node
-
Execute Operations — Once the required data is read into memory, it flows through a pipeline of the nodes in your physical plan. There is more than 50 years of work in building optimizations for these steps as applied to different data structures and in-memory representations; everything from row-oriented databases, to columnar, to time series to geo-spatial to graph. But fundamentally, there are 5 common operations:
-
Projection — Extract only the columns or expressions that the user requested needed (e.g.
order_id). -
Filtering — Rows that don’t meet your
WHEREcondition are dropped. -
Joining — If your query involves multiple tables, the engine merges or joins them—this could be a hash join, sort-merge join, or even a nested loop join depending on data statistics.
-
Aggregation — If you have an aggregation like
SUM(amount)orCOUNT(*), the engine groups rows by the specified columns and calculates the aggregated values. -
Sorting / Window Functions — If the query uses
ORDER BY,RANK(), or other window functions, the data flows into those operators next.
-
-
Merge and return results — The last mile step is generating the tabular dataset. In the case of distributed systems, this may require combining the results from several nodes into a single result.
Finally! Actionable business insights, right in the palm of your hand!
Looking ahead
That’s probably more about databases that you bargained for! I know this is a lot to absorb - but the best data practitioners have a deep understanding of their tools and this is all extremely relevant for understanding the next evolution of data tooling and data work. Next time you run a query, don't forget to thank your database for all the hard work it's doing for you.
Comments